Hortonworks est l’un des acteurs majeurs dans le domaine de la distribution Hadoop dans le monde, et le seul pour le moment à s’intéresser à l’écosystème Microsoft, en proposant 2 offres orientées Cloud ou On-Premise :
- Hortonworks Data Platform (HDP), à installer soit-même, et donc plutôt on-premise (rien ne vous empêche cependant de stocker les machines dans le cloud), version qui nous intéresse aujourd’hui.
- HDInsight, basé sur HDP, produit par Microsoft et disponible dans Azure.
HDInsight est facile à mettre en oeuvre car il ne nécessite aucune installation à proprement parler, il suffit juste de créer des stockage et le cluster dans Azure. Ce qui se fait en quelques clics (on trouve pas mal de tuto sur les blogs, celui de Romain par exemple)
L’idée, dans cet article, est de regarder comment se passe l’installation d’HDP sur un serveur Windows Server 2012. On va rester sur le cas simple d’un serveur simple nœud.
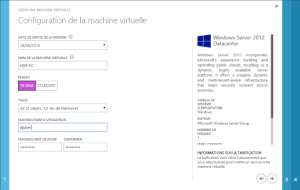
Commençons par créer la machine virtuelle dans Azure (Windows Server 2012 Datacenter, Taille A2)
Une fois la machine créée, on y uploade :
- le zip contenant les fichiers d’install d’HDP (à downloader ici)
- le JDK de Java (mini version 7), Python (mini version 2.7) et les packages Visual C++ distributable, tous étant des pré-requis à l’installation
La version 4.0 du Framework .NET est également requise, mais une version plus récente est déjà installée sur Windows Server 2012.
Installer les pré-requis
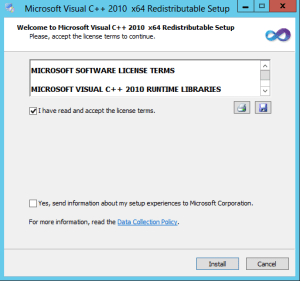
Visual C++ s’installe par double-clic.
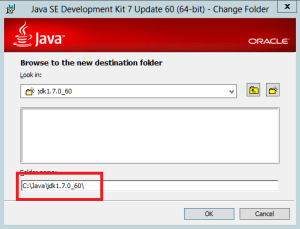
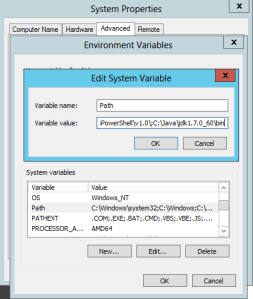
Pour Java, il est impératif de ne pas avoir d’espace dans le path du répertoire d’installation (et donc de ne pas garder le répertoire par défaut en « Program Files »)
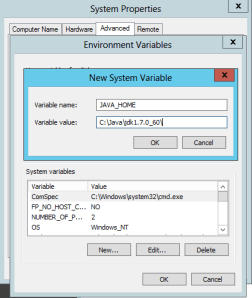
De même, une fois Java installé, il faut créer une variable d’environnement qui mappe le répertoire, et rajouter le \bin au PATH :
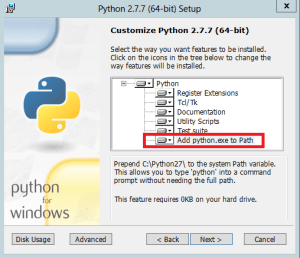
Pour Python, c’est du double-clic aussi, juste faire attention à rajouter l’installation de l’exe qui n’est pas sélectionnée par défaut.
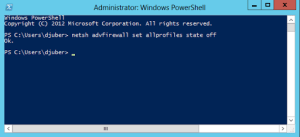
Enfin pour finir les pré-requis et ne pas se générer de problème supplémentaire, on va désactiver le pare-feu Windows :
Installer Hortonworks Data Platform
On est enfin prêt à passer à l’installation effective de HDP.
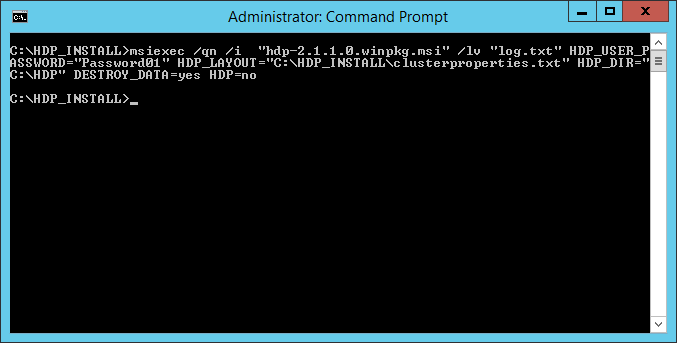
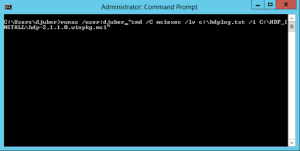
Dans une commande prompt, il faut lancer l’instruction suivante :
runas /user:djuber « cmd /C msiexec /lv c:\hdplog.txt /i C:\HDP_INSTALL\hdp-2.1.0.0.winpkg.msi »
où djuber doit être votre compte administrateur et C:\HDP_INSTALL le dossier où vous avez extrait le zip d’HDP que vous aviez téléchargé.
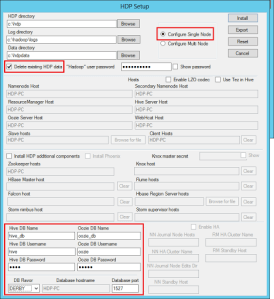
Cela ouvre la page de setup d’HDP :
Si les répertoires d’installation par défaut vous conviennent, n’y touchez pas. Choisissez « Configure Single Node ».
Le « Delete existing HDP Data » n’est pas forcément nécessaire dans notre cas, mais il assure que le HDFS sera formaté.
Enfin la dernière partie concerne la configuration des bases Hive et Oozie (Pensez à choisir DERBY comme base de données si vous n’avez pas de SQL Server sous la main).
On peut enfin lancer l’installation.
 |
| Un panneau Warning pour vous dire que l’installation a réussi, c’est assez original |
Votre cluster Hadoop (simple noeud) est désormais fonctionnel, il ne vous reste plus qu’à lancer les services et lancer un batch pour vérifier qu’il fonctionne
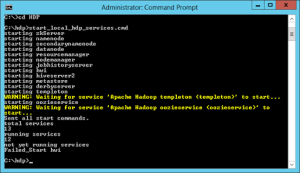
Lancer les services :
Placer vous dans le répertoire c:\HDP (si vous n’avez pas touché aux répertoires par défaut) et lancer l’instruction suivante :
start_local_hdp_services.cmd
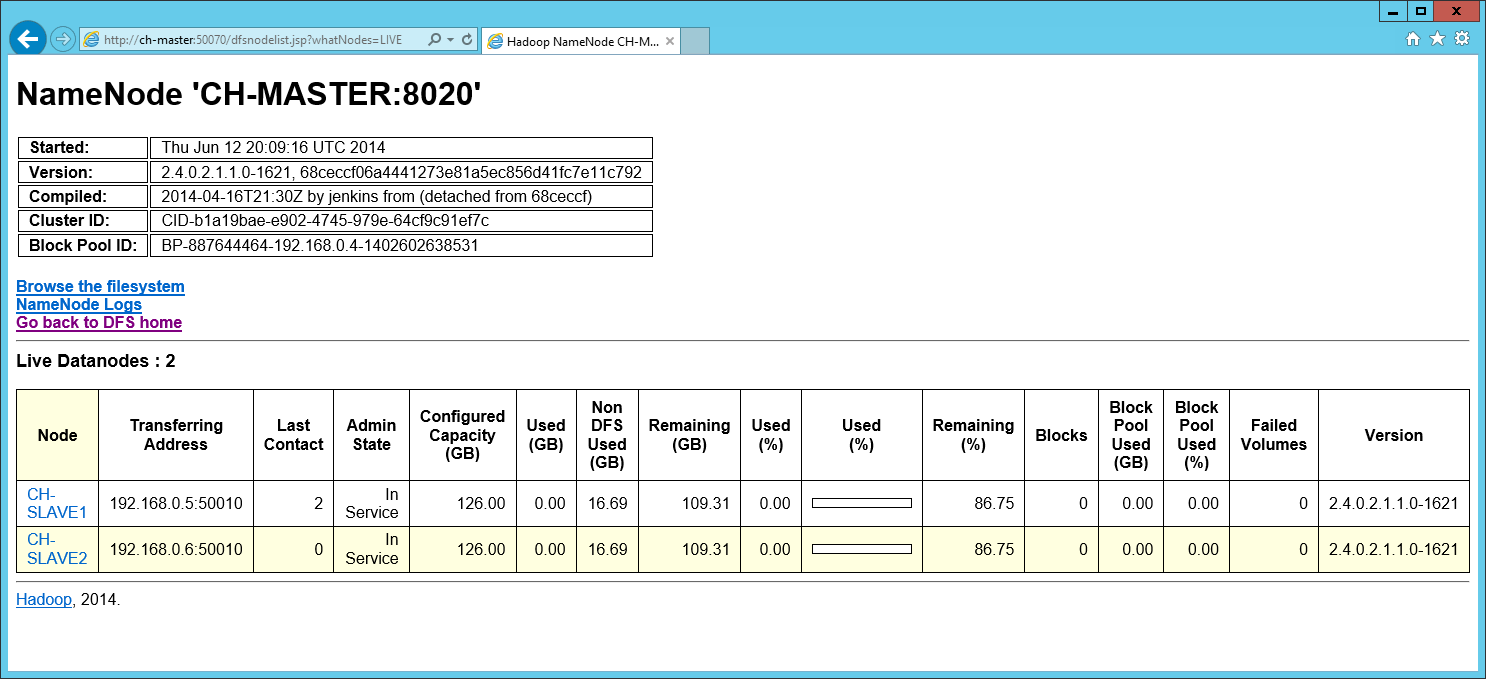
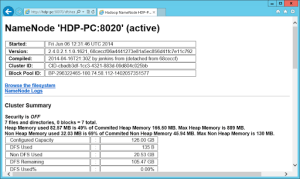
On peut désormais vérifier que le serveur est actif en cliquant sur la page web disponible sur le bureau (Hadoop Name Node Status)
Lancer un batch
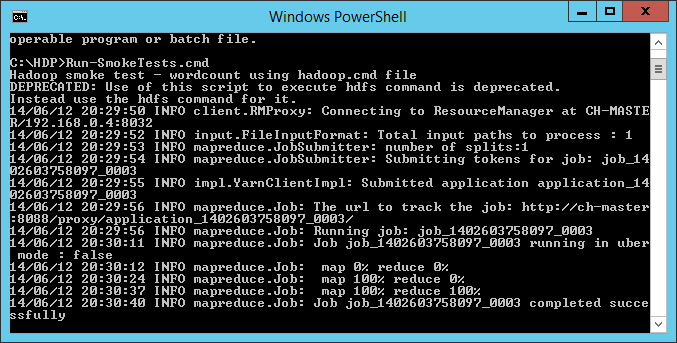
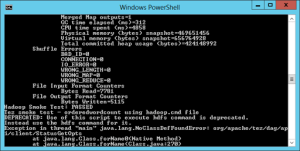
Il ne reste qu’à lancer un petit batch de map/reduce (fourni par HDP) pour tester notre cluster :
il faut lancer la console Hadoop (créée sur le bureau également) en mode administrateur et exécuter la commande suivante :
Run-SmokeTests.cmd
Quelques tests plantent car je n’ai pas installé tous les add-in.
En bref
L’installation n’est donc pas compliquée en soit, il faut bien respecter les pré-requis. Néanmoins quelques erreurs peuvent se produire, et il n’est pas toujours évident de trouver de la littérature sur le sujet.
C’est là où HDInsight est vraiment intéressant en permettant d’outrepasser toute difficulté d’installation.