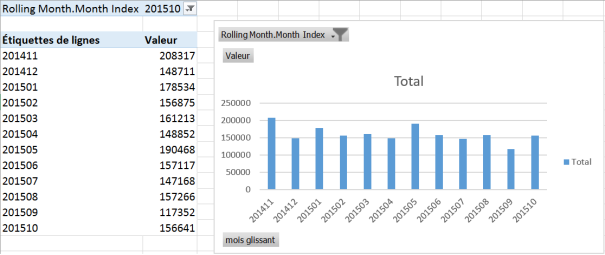
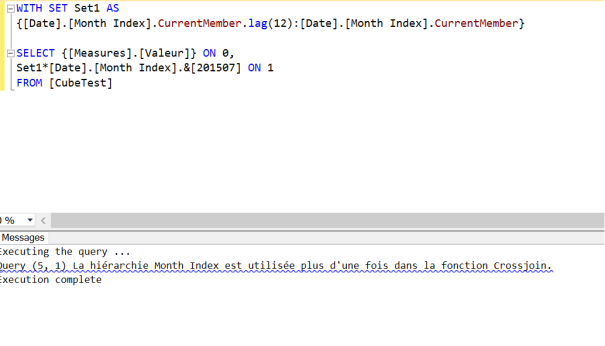
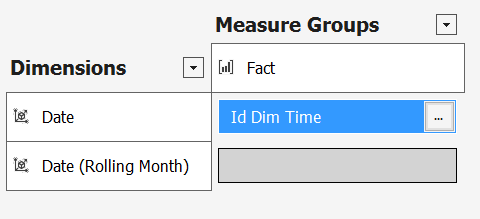
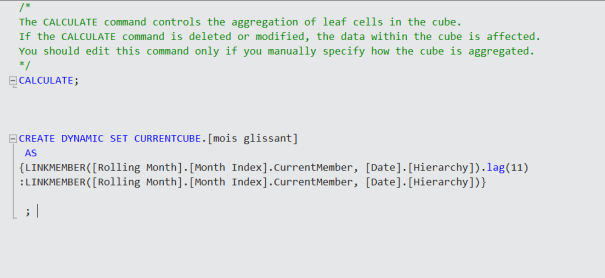
Plus qu’une semaine de cours, et j’aurai terminé le cours en ligne Machine Learning de Coursera. Je résiste pas à l’idée de vous faire un petit feedback.

Coursera
Alors Coursera, c’est la plateforme de cours en ligne lancée en Avril 2012 et proposant des partenariats avec plusieurs universités américaines comme Stanford ou Princeton. On retrouve également maintenant des écoles françaises comme Polytechnique, Centrale ou l’ENS. Bref plutôt le haut du panier.
Ces universités proposent des cours en ligne donc, sur des périodes de 4 à 15 semaines (j’ai vu 14 semaines, il y a peut-être plus) ouverts plusieurs fois dans l’année.
Certaines formations sont payantes, mais proposent en contrepartie un certificat vérifié (ou une assistance technique dédiée et quelques fonctionnalités supplémentaires).
Machine Learning
Le cours de Machine Learning est proposé par l‘université de Stanford et dispensé par Andrew Ng (un des fondateurs de Coursera). Il est gratuit et se déroule sur 10 semaines. Le travail estimé est entre 5 et 7 heures par semaine. La formation se déroule en anglais, mais est sous-titrée en plusieurs langues (pas en français malheureusement)
Chaque semaine, une liste de vidéos est mise en ligne. Chaque vidéo dure entre 5 et 15 minutes, vous pouvez les regarder en streaming ou les télécharger. Au cours de la lecture, vous avez une question qui correspond soit à une application directe de ce que vous venez de regarder, soit à l’introduction de la suite de la vidéo.
Une fois toutes les vidéos de la semaine lues, vous pouvez répondre à un quiz de 5 questions qui sont une application assez directe du cours. A noter qu’il est noté sur 5 points et que vous avez 100 essais pour les réussir (c’est très large, dans les faits, vous devriez faire entre 1 et 5 essais si vous êtes attentifs).
Et régulièrement (il doit y avoir juste 2 ou 3 semaines où ça n’est pas le cas), vous avez un exercice de programmation sous Octave (logiciel mathématique équivalent à MatLab, très prisé des data-scientists si on croit Andrew). Il y a un système de soumission en ligne pour valider vos programmes, et un système de points à obtenir.
Feedback
Le cours permet d’appréhender le machine learning et de savoir de quoi on parle lorsqu’on utilise les outils (qui a parlé de Azure Machine Learning ?), mais est plutôt orienté théorie au final : on ne fait pas qu’utiliser les algorithmes, on les construit, on les teste, on les optimise. Si vous souhaitez juste découvrir ce qu’est le machine learning, je ne crois pas que ce soit la meilleure manière de faire.
Les 5 à 7 heures de travail par semaine sont plutôt un minimum qu’une moyenne : on peut les dépasser si on lutte un peu sur les exercices de programmation (ce qui est parfois le cas). Je pense qu’il faut avoir conscience que ce cours demande une certaine quantité de travail pour être suivi.
Le cours ne demande qu’un léger pré-requis en programmation dans sa description. Je crois qu’il serait opportun de rajouter un léger background en mathématiques. En effet, on manipule beaucoup d’algèbre linéaire (matrice, vecteurs, …) et un peu de statistiques. De plus assez régulièrement, Andrew choisit de donner un résultat sans s’encombrer de preuve mathématique (volontairement), mais ça peut être intéressant de comprendre comment il arrive à ces résultats.
Il y a parfois des longueurs dans les vidéos : on peut avoir l’impression que les mêmes choses se répètent alors qu’en vérité, il y a une petite différence (rajout d’une propriété dans un algorithme, choix d’une autre variable), ou l’impression que le formateur explique en 5 minutes quelque chose qu’il pourrait énoncer en 30 secondes sans nécessairement entrer dans les détails.
Mais au final, le cours est intéressant avec des exercices de programmation plutôt pertinents qui donnent des applications concrètes du machine learning (reconnaissance d’écriture, moteur de recommandation, prédiction de prix,…) et qui ne demandent qu’à être testés sur nos propres jeux de données.
Bref, je ne regrette pas du tout de l’avoir suivi, et j’en redemande car je me suis inscrit au premier cours du cursus Data Science (payant celui-ci) de l’université Johns Hopkins.