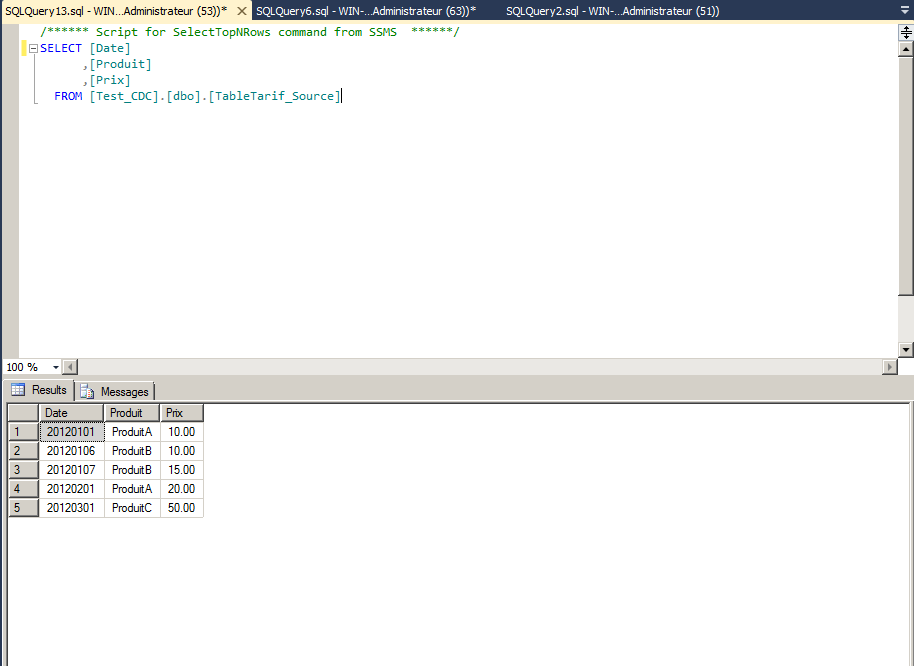
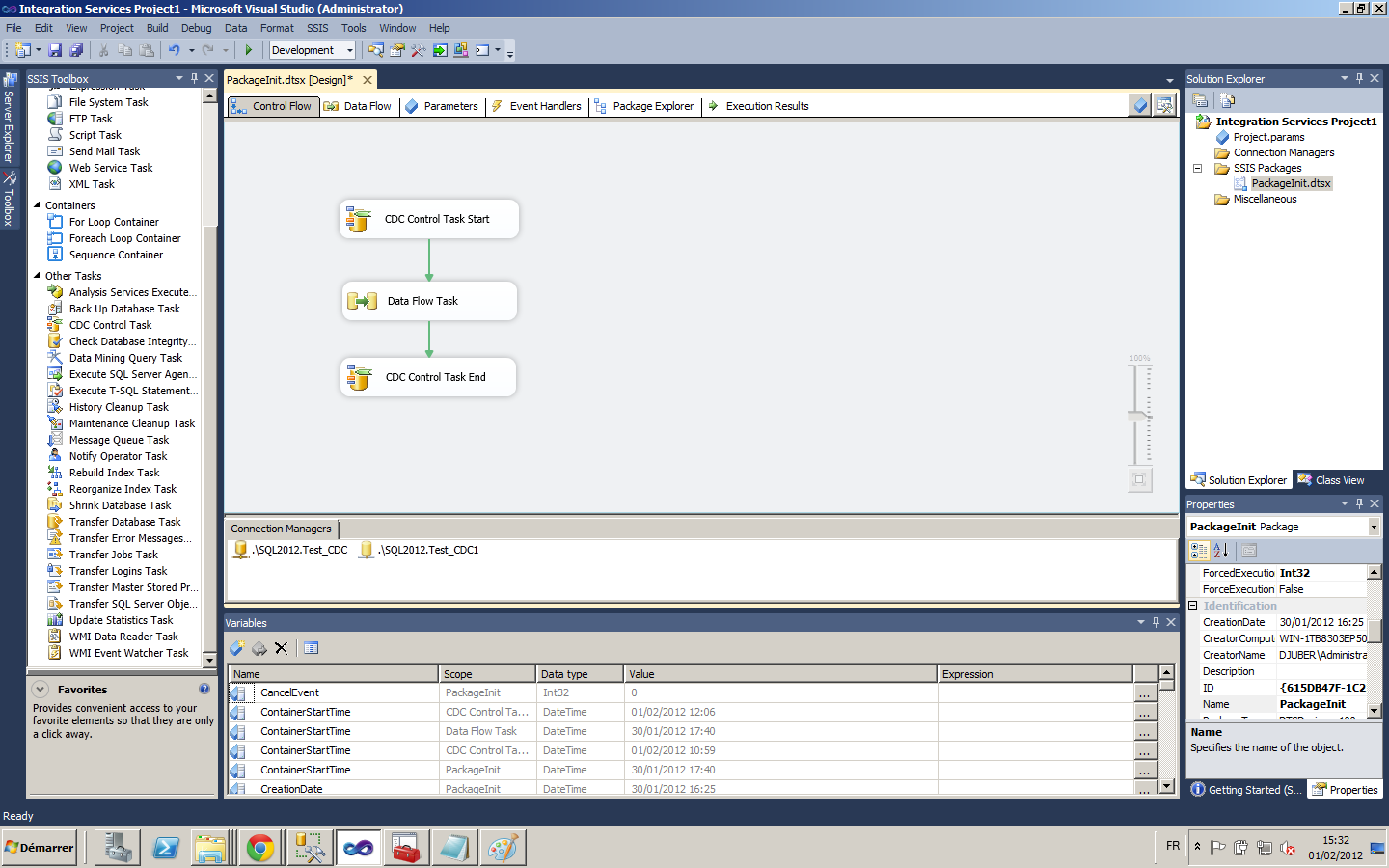
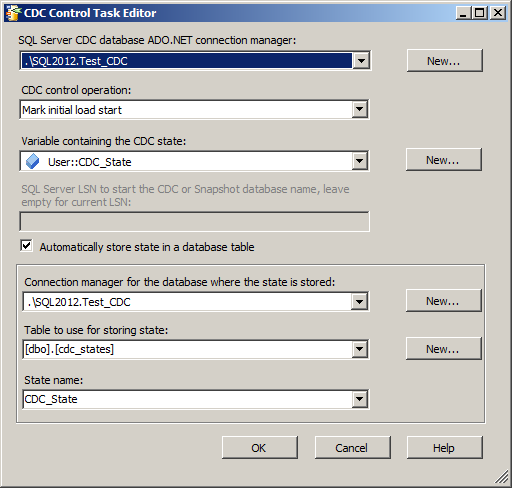
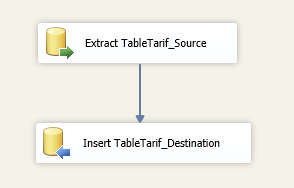
La communauté SQL francophone organise à Paris dans les locaux Microsoft les journées SQL Server qui se tiendront les 12 & 13 Décembre 2011.
Les sessions promettent d’être intéressantes avec la distinction de deux types de parcours* (un parcours moteur SQL et un parcours Business Intelligence).
* Un parcours appliance a été ajouté.
Je suivrai en particulier le parcours BI avec notamment la présence de deux collègues en tant que speaker, messieurs Sébastien Madar et Florian Eiden.
Inscription via le lien suivant :
Journées SQL Server
Je suivrai précisemment ce parcours :
lundi 12 décembre 2011 :
10:00 S121 – La Business Intelligence avec SQL Server 2012
Tour d’horizon de toutes les nouveautés BI de SQL Server 2012, de BISM à Power View (projet Crescent) en passant par SSIS et le nouveau moteur de qualité de données DQS. Cette session introduit l’ensemble des choses que vous verrez pendant l’événeme … More
Tour d’horizon de toutes les nouveautés BI de SQL Server 2012, de BISM à Power View (projet Crescent) en passant par SSIS et le nouveau moteur de qualité de données DQS. Cette session introduit l’ensemble des choses que vous verrez pendant l’événement.
11:45 S122 – Décider entre Tabular ou Multidimensional pour un projet Analysis Services
Cette session se focalise sur les différences entre le nouveau modèle BISM et le modèle UDM classique. Qu’est ce qui change ? Dois-je refaire mes projets décisionnels ? Dois-je apprendre un nouvel outil ? Découvrez tout ce qu’il faut savoir sur la n … More
Cette session se focalise sur les différences entre le nouveau modèle BISM et le modèle UDM classique. Qu’est ce qui change ? Dois-je refaire mes projets décisionnels ? Dois-je apprendre un nouvel outil ? Découvrez tout ce qu’il faut savoir sur la nouvelle version d’Analysis Services dans SQL Server 2012 au travers de cette session.
14:00 S123 – Power View, Powerpivot : voir ses données autrement
Power View (projet Crescent) est la nouvelle évolution dans la famille des outils de restitution de données Microsoft. Découvrez ce nouvel outil qui permet la création de tableaux de bord très riches et dynamiques. Dans cette session, découvrez égal … More
Power View (projet Crescent) est la nouvelle évolution dans la famille des outils de restitution de données Microsoft. Découvrez ce nouvel outil qui permet la création de tableaux de bord très riches et dynamiques. Dans cette session, découvrez également sa collaboration avec PowerPivot. Ensemble, ces 2 outils donnent du pouvoir aux utilisateurs afin de maitriser leurs besoins décisionnels.
15:45 S124- SQL Server & Sharepoint : le couple de l’année
Venez découvrir dans cette session les spécificités de l’architecture, de la gestion et du décisionnel dans un contexte SQL Server associé à SharePoint. Les produits suivants seront couverts : SQL Server 2008 R2, SQL Server 2012, Power View (projet … More
Venez découvrir dans cette session les spécificités de l’architecture, de la gestion et du décisionnel dans un contexte SQL Server associé à SharePoint. Les produits suivants seront couverts : SQL Server 2008 R2, SQL Server 2012, Power View (projet Crescent), SharePoint 2010, SQL Server Reporting Services, Excel Services, PowerPivot, Performance Point Services, etc.
17:15 ColumnStore Index : une nouvelle façon d’indexer vos Datawarehouse
Connu sous le nom de code Apollo, SQL Server 2012 apporte une grande nouveauté dans l’indexation des bases de données : les index de type colonne. Venez découvrir cette fonctionnalité et comment elle peut améliorer grandement vos performances avec l … More
Connu sous le nom de code Apollo, SQL Server 2012 apporte une grande nouveauté dans l’indexation des bases de données : les index de type colonne. Venez découvrir cette fonctionnalité et comment elle peut améliorer grandement vos performances avec le cas d’utilisation d’un DatawareHouse.
mardi 13 décembre 2011 :
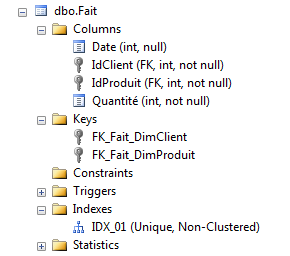
10:00 S221 – Modélisation dimensionnelle : le fondement du datawarehouse
Etoiles, flocons, granularité, faits, dimensions, mesures… c’est le vocabulaire du décisionnel, ce sont les éléments de base du datawarehouse. Kimball & Inmon, ce sont les précurseurs qui ont définit comment penser ses dimensions, comment modéliser … More
Etoiles, flocons, granularité, faits, dimensions, mesures… c’est le vocabulaire du décisionnel, ce sont les éléments de base du datawarehouse. Kimball & Inmon, ce sont les précurseurs qui ont définit comment penser ses dimensions, comment modéliser ses tables et ses colonnes pour bien répondre au besoin d’analyse. Avec SQL Server 2012 et son modèle tabulaire, ce modèle de conception est-il remis en cause ? Et que dire des autres courants comme Data Vault, Hadoop et consorts ? Cette session fait le tour de ces notions et des modélisations existantes. Elle présente les concepts essentiels à prendre en compte pour bien construire sa solution décisionnelle, que ce soit en termes de justesse de l’analyse, d’efficacité pour le stockage ou de temps de réponse. Cette session s’adresse aux nouveaux venus du décisionnel, aux autodidactes n’ayant jamais pu acquérir la théorie ou encore aux consultants confirmés qui souhaitent se mettre à jour sur les bonnes pratiques de la modélisation dimensionnelle.
11:45 S222 – Les nouveautés SSIS dans SQL Server 2012
SSIS bénéficie de nombreuses améliorations dans la prochaine version de SQL Server (nouveaux designers, mode projet, etc.). Venez découvrir toutes ces nouveautés qui enrichissent cet outil de manipulation de données, indispensable dans les projets … More
SSIS bénéficie de nombreuses améliorations dans la prochaine version de SQL Server (nouveaux designers, mode projet, etc.). Venez découvrir toutes ces nouveautés qui enrichissent cet outil de manipulation de données, indispensable dans les projets décisionnels mais aussi très pratique dans de nombreuses tâches de développement.
14:00 S213 – Contraintes et performances
Une idée solidement ancrée dans l’esprit des informaticiens est que la vérification des contraintes « gâche du temps » d’exécution, tant est si bien que certains évite de les poser. Nous verrons quel est le coût exact d’une contrainte, quel perte de t … More
Une idée solidement ancrée dans l’esprit des informaticiens est que la vérification des contraintes « gâche du temps » d’exécution, tant est si bien que certains évite de les poser. Nous verrons quel est le coût exact d’une contrainte, quel perte de temps elle entraîne, comment minimiser leur temps d’exécution et comment la plupart des contraintes SQL permettent de vous faire gagner un temps considérable… Après cet exposé, vous n’aurez plus qu’une seule envie : poser le maximum de contraintes dans votre base de données !
15:45 S224- MDS et DQS : données d’entreprise
Tour d’horizon de SQL Server 2012 Master Data Services et Data Quality Services, où nous verrons comment mettre en place un référentiel de données d’entreprise et d’un système de qualité de données tout cela dans une démarche de Master Data Manageme … More
Tour d’horizon de SQL Server 2012 Master Data Services et Data Quality Services, où nous verrons comment mettre en place un référentiel de données d’entreprise et d’un système de qualité de données tout cela dans une démarche de Master Data Management.